· Shane Trimbur
Multi-Modal Beamforming and AI Compression: A Roadmap for 6G-Ready V2X Resilience
A new approach to vehicle-to-everything (V2X) networks fuses RF, vision, and LiDAR while compressing AI models for edge deployment. Here's how modality generation and lightweight design will shape 6G communications.
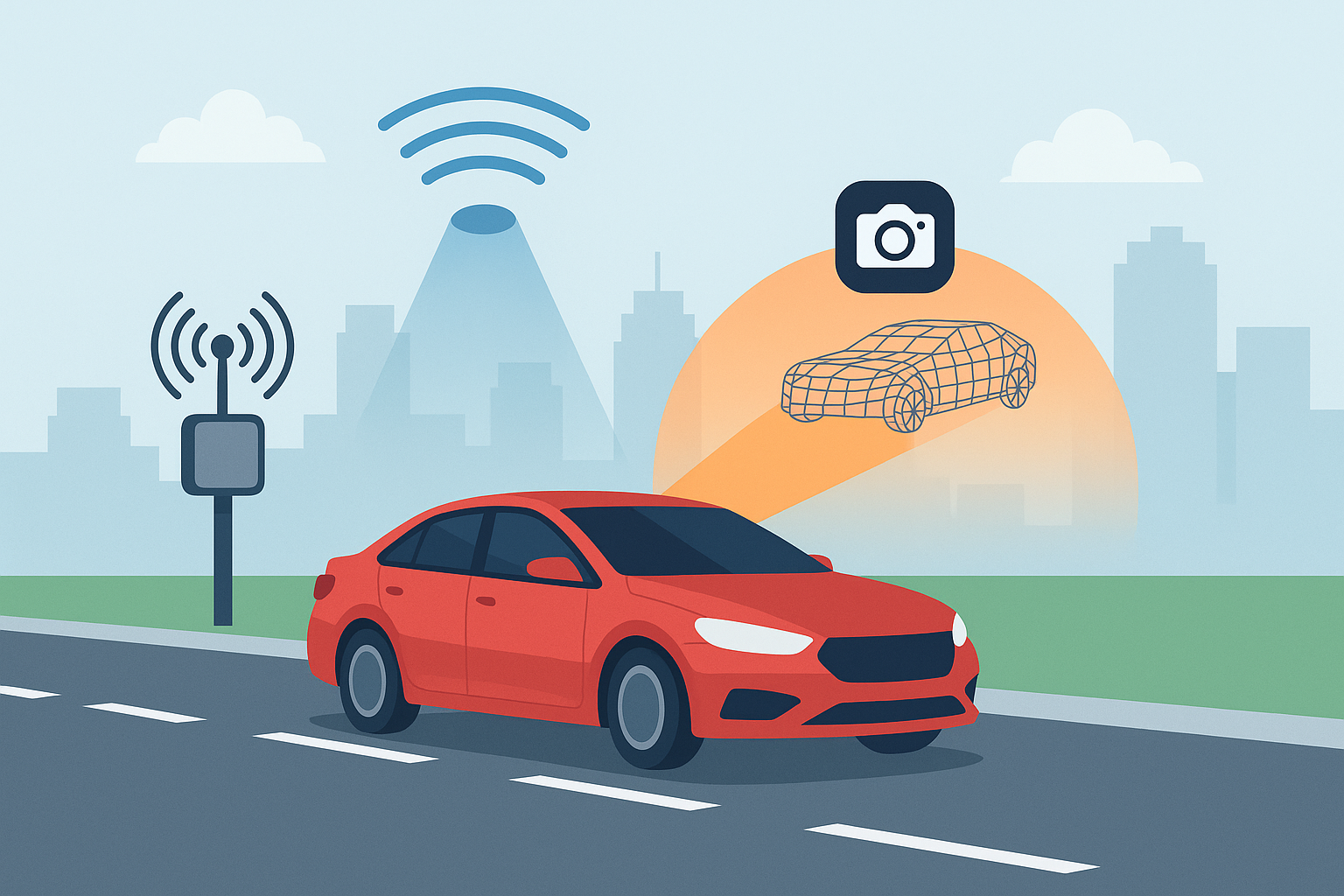
Beyond RF: The Future of Beamforming in a 6G World
In a groundbreaking study (arXiv:2506.22469), researchers Shang, Hoang, and Yu reveal a method for enabling multi-modal beamforming in 6G Vehicle-to-Everything (V2X) networks by integrating RF, LiDAR, and camera inputs—then compressing these models for real-time, low-latency execution on edge devices.
Their model also includes an ingenious fail-safe: when any modality fails or drops out, a learned modality generator synthesizes the missing input. The result is a system that can predict beam directions even under degraded conditions, perfect for the variable and unreliable sensor environments common in autonomous vehicle deployments.
🚗 The Problem: RF Alone Isn’t Enough
Predictive beamforming is vital for minimizing packet loss and maximizing throughput in mobile environments. Traditional solutions focus solely on RF signal features, but that’s brittle—especially in dense, fast-moving, or occluded scenarios. In V2X applications, sensor dropout is a given, and systems must adapt in milliseconds.
🧠 The Solution: Three-Pronged Innovation
1. Multi-Modal Fusion
They combine:
- RF baseband data
- Visual scene understanding (camera)
- Spatial depth from LiDAR
This combination creates a richer environmental model, enabling more precise beam direction estimation.
2. Modality Generation
If the camera malfunctions or LiDAR becomes unreliable (say, due to fog or occlusion), a modality generation network fills in missing modalities, allowing the system to recover and operate continuously.
3. AI Model Compression
For real-world deployment, large neural networks are compressed using:
- Pruning
- Quantization
This ensures the entire system runs on constrained on-vehicle hardware—without losing predictive accuracy.
🔍 Real-World Impact
| Feature | Traditional Beamforming | This Method |
|---|---|---|
| Modal Inputs | RF-only | RF + Camera + LiDAR |
| Fault Tolerance | None | Modality Generation |
| Edge Deployment | Difficult | Achieved via Compression |
| Accuracy | Moderate | High in occlusion/urban |
📡 Use Cases on the Edge
- Urban Autonomous Driving Handles sensor occlusion from buildings and buses.
- Fleet Logistics AI Enables robust communications in mixed-sensor legacy fleets.
- Military Convoy Operations Ensures predictive beamforming continuity under electronic warfare or terrain interference.
- Remote Emergency Response Resilient sensor fusion for first responders in rugged environments.
- Next-Gen Traffic Infrastructure Connects AI-based infrastructure to vehicles with variable modality availability.
🔮 Why It Matters for Edge AI Designers
The implications go far beyond vehicles. This architecture is a blueprint for resilient edge AI systems:
- Accept multiple imperfect inputs.
- Generate synthetic data when needed.
- Shrink inference models to run on chips.
- Recover from sensor loss in real time.
In other words, don’t treat AI as fragile. Build it to adapt.
🔧 Implementation Roadmap
- Model Architecture Use a multi-stream network with parallel branches for each modality.
- Training Strategy Augment with dropout-style masking during training to teach modality synthesis.
- Compression Apply pruning + quantization post-training with edge constraints in mind.
- Deployment Use TensorRT or ONNX runtime for fast inference on NVIDIA Jetson or similar hardware.
🧩 Final Thought
This study quietly marks the beginning of a fault-tolerant, self-healing AI infrastructure—essential for any system operating in noisy, chaotic, or adversarial physical environments. As we build the next generation of 6G communications and autonomous infrastructure, multi-modal learning with modality generation and compression is not optional—it’s foundational.